Rangkuman Hash Table dan Binary Tree
Hashing
Hashing adalah teknik yang digunakan untuk menyimpan dan mengambil kunci dengan cepat.
Dalam hashing, string karakter ditransformasikan menjadi nilai panjang yang biasanya lebih
pendek atau kunci yang mewakili string asli.
Hashing digunakan untuk mengindeks dan mengambil item dalam database karena lebih cepat
menemukan item menggunakan kunci hash yang lebih pendek daripada menemukannya
menggunakan nilai asli.
Hashing juga dapat didefinisikan sebagai konsep mendistribusikan kunci dalam array yang
disebut tabel hash menggunakan fungsi yang telah ditentukan yang disebut fungsi hash.
Hash Table
merupakan salah satu struktur data yang digunakan dalam penyimpanan data sementara. Tujuan dari hash table adalah untuk mempercepat pencarian kembali dari banyak data yang disimpan. Hash table menggunakan suatu teknik penyimpanan sehingga waktu yang dibutuhkan untuk penambahan data (insertions), penghapusan data (deletions), dan pencarian data (searching) relatif sama dibanding struktur data atau algoritma yang lain.

Itu merupakan tabel hashdari string itu. atan disimpan dalam h [0] karena a adalah 0. char disimpan dalam h [2] karena c adalah 2. define disimpan dalam h [3] karena d adalah 3. dan seterusnya.. kita hanya mempertimbangkan karakter pertama dari setiap string.
Deklarasi utama hash tabel adalah dengan struct, yaitu:
typedef struct hashtbl {
hash_size size;
struct hashnode_s **nodes;
hash_size (*hashfunc)(const char *);
} HASHTBL;
Anggota simpul pada hashtbl mempersiapkan penunjuk kepada unsur pertama yang terhubung dengan daftar. unsur ini direpresentasikan oleh struct hashnode_:
struct hashnode_s {
char *key;
void *data;
struct hashnode_s *next;
};
Inisialisasi
Deklarasi untuk inisialisasi hash tabel seperti berikut:
HASHTBL *hashtbl_create(hash_size size, hash_size
(*hashfunc)(const char *))
{
HASHTBL *hashtbl;
if(!(hashtbl=malloc(sizeof(HASHTBL)))) return NULL;
free(hashtbl);
return NULL;
}
hashtbl->size=size;
if(hashfunc) hashtbl->hashfunc=hashfunc;
else hashtbl->hashfunc=def_hashfunc;
return hashtbl;
}
Cleanup
Hash Tabel dapat menggunakan fungsi linked lists untuk menghapus element
atau daftar anggota dari hash tabel .
Deklarasinya:
void hashtbl_destroy(HASHTBL *hashtbl)
{
hash_size n;
struct hashnode_s *node, *oldnode;
for(n=0; n<hashtbl->size; ++n) {
node=hashtbl->nodes[n];
while(node) {
free(node->key);
oldnode=node;
node=node->next;
free(oldnode);
}
}
free(hashtbl->nodes);
free(hashtbl);
}
Menambah Elemen Baru
Untuk menambah elemen baru maka harus menentukan ukuran pada hash tabel. Dengan deklarasi sebagai berikut:
int hashtbl_insert(HASHTBL *hashtbl, const char *key, void
*data)
{
struct hashnode_s *node;
hash_size hash=hashtbl->hashfunc(key)%hashtbl->size;
Penambahan elemen baru dengan teknik pencarian menggunakan linked lists
untuk mengetahui ada tidaknya data dengan key yang sama yang
sebelumnya sudah dimasukkan, menggunakan deklarasi berikut:
node=hashtbl->nodes[hash];
while(node) {
if(!strcmp(node->key, key)) {
node->data=data;
return 0;
}
node=node->next;
}
Jika tidak menemukan key yang sama, maka pemasukan elemen baru pada
linked lists dengan deklarasi berikut:
if(!(node=malloc(sizeof(struct hashnode_s)))) return -1;
if(!(node->key=mystrdup(key))) {
free(node);
return -1;
}
node->data=data;
node->next=hashtbl->nodes[hash];
hashtbl->nodes[hash]=node;
return 0;
}
Menghapus sebuah elemen
Untuk menghapus sebuah elemen dari hash tabel yaitu dengan mencari nilai hash menggunakan deklarasi linked list dan menghapusnya jika nilai tersebut ditemukan. Deklarasinya sebagai berikut:
int hashtbl_remove(HASHTBL *hashtbl, const char *key)
{
struct hashnode_s *node, *prevnode=NULL;
hash_size hash=hashtbl->hashfunc(key)%hashtbl->size;
node=hashtbl->nodes[hash];
while(node) {
if(!strcmp(node->key, key)) {
free(node->key);
if(prevnode) prevnode->next=node->next;
else hashtbl->nodes[hash]=node->next;
free(node);
return 0;
}
prevnode=node;
node=node->next;
}
return -1;
}
Searching
Teknik pencarian pada hash tabel yaitu dengan mencari nilai hash yang sesuai menggunakan deklarasi sama seperti pada linked list. Jika data tidak
ditemukan maka menggunakan nilai balik NULL. Deklarasinya sebagai berikut:
void *hashtbl_get(HASHTBL *hashtbl, const char *key)
{
struct hashnode_s *node;
hash_size hash=hashtbl->hashfunc(key)%hashtbl->size;
node=hashtbl->nodes[hash];
while(node) {
if(!strcmp(node->key, key)) return node->data;
node=node->next;
}
return NULL;
}
Resizing
Jumlah elemen pada hash tabel tidak selalu diketahui ketika terjadi penambahan data. Jika jumlah elemen bertambah begitu besar maka itu akan mengurangi operasi pada hash tabel yang dapat menyebabkan terjadinya kegagalan memory. Fungsi Resizing hash tabel digunakan untuk mencegah terjadinya hal itu.Dekalarsinya sebagai berikut:
int hashtbl_resize(HASHTBL *hashtbl, hash_size size)
{
HASHTBL newtbl;
hash_size n;
struct hashnode_s *node,*next;
newtbl.size=size;
newtbl.hashfunc=hashtbl->hashfunc;
if(!(newtbl.nodes=calloc(size, sizeof(struct
hashnode_s*)))) return -1;
for(n=0; n<hashtbl->size; ++n) {
for(node=hashtbl->nodes[n]; node; node=next) {
next = node->next;
hashtbl_insert(&newtbl, node->key,
node->data);
hashtbl_remove(hashtbl, node->key);
}
}
free(hashtbl->nodes);
hashtbl->size=newtbl.size;
hashtbl->nodes=newtbl.nodes;
return 0;
}
Lookup pada Hash table
Salah satu keunggulan struktur hash table dibandingkan dengan struktur tabel biasa adalah kecepatannya dalam mencari data. Terminologi lookup mengacu pada proses yang bertujuan untuk mencari sebuah record pada sebuah tabel, dalam hal ini adalah hash table.
Dengan menggunakan hash function, sebuah lokasi dari record yang dicari
bisa diperkirakan. Jika lokasi yang tersebut berisi record yang dicari, maka
pencarian berhasil. Inilah kasus terbaik dari pencarian pada hash table. Namun, jika record yang hendak dicari tidak ditemukan di lokasi yang diperkirakan, maka akan dicari lokasi berikutnya sesuai dengan kebijakan resolusi bentrokan. Pencarian akan berhenti jika record ditemukan, pencarian bertemu dengan tabel kosong, atau pencarian telah kembali ke lokasi semula.
Collision (Tabrakan)
Keterbatasan tabel hash menyebabkan ada dua angka yang jika dimasukkan ke dalam fungsi hash maka menghasilkan nilai yang sama. Hal ini disebut dengan collision.
contoh: Kita ingin memasukkan angka 6 dan 29.
Hash(6) = 6 % 23 = 6
Hash(29)= 29 % 23 = 6
Untuk meminimalkan collision gunakan hash function yang dapat mencapai seluruh indeks/alamat. Dalam contoh di atas gunakan m untuk me-modulo k. Perhatikan bila kita menggunakan angka m untuk me-modulo k maka pada indeks yang lebih besar dari dan sama dengan m di hash table tidak akan pernah terisi (memori yang terpakai semakin kecil), kemungkinan terjadi collision juga semakin besar.
Karena memori yang terbatas dan untuk masukan data yang belum diketahui tentu collision tidak dapat dihindari.
Berikut ini cara-cara yang digunakan untuk mengatasi collision :
1. Closed hashing (Open Addressing)
Close hashing menyelesaikan collision dengan menggunakan memori yang masih ada tanpa menggunakan memori diluar array yang digunakan. Closed hashing mencari alamat lain apabila alamat yang akan dituju sudah terisi oleh data. 3 cara untuk mencari alamat lain tersebut :
- Ø Linear Probing
struct { ... } node;
node Table[M]; int Free;
/* insert K */
addr = Hash(K);
if (IsEmpty(addr)) Insert(K,addr);
else {
/* see if already stored */
test:
if (Table[addr].key == K) return;
else {
addr = Table[addr].link; goto test;}
/* find free cell */
Free = addr;
do { Free--; if (Free<0) Free=M-1; }
while (!IsEmpty(Free) && Free!=addr)
if (!IsEmpty(Free)) abort;
else {
Insert(K,Free); Table[addr].link = Free;}
- Ø Quadratic Probing
Quadratic Probing mencari alamat baru untuk ditempati dengan proses perhitungan kuadratik yang lebih kompleks. Tidak ada formula baku pada quadratic probing ini,anda dapat menentukan sendiri formula yang akan digunakan.
Contoh formula quadratic probing untuk mencari alamat baru:
h,(h+i2)mod m,(h-i2)mod m, … ,(h+((m-1)/2)2)mod m, (h-((m-1)/2)2)mod m
dengan i = 1,2,3,4, … , ((m-1)/2)
Mksud formula di atas adalah jika alamat h telah terisi, maka alamat lain yang digunakan adalah (h+1)mod m, jika telah terisi gunakan alamat (h-1)mod m, jika telah terisi gunakan alamat (h+4)mod m, jika telah terisi gunakan alamat (h-4)mod m, dan seterusnya.
Jadi jika m=23,maka nilai maksimal i adalah : ((23-1)/2)=11.
- Double hashing
Sesuai dengan namanya, alamat baru untuk menyimpan data yang belum dapat masuk ke dalam table diperoleh dengan menggunakan hash function lagi. Hash function kedua yang digunakan setelah alamat yang dihasilkan oleh hash function awal telah terisi tentu saja berbeda dengan hash function awal itu sendiri.
Kelemahan dari closed hashing adalah ukuran array yang disediakan harus lebih besar dari jumlah data. Selain itu dibutuhkan memori yang lebih besar untuk meminimalkan collision.
2. Open hashing (Separate Chaining)
Pada dasarnya separate chaining membuat tabel yang digunakan untuk proses hashing menjadi sebuah array of pointer yang masing-masing pointernya diikuti oleh sebuah linked list, dengan chain (mata rantai) 1 terletak pada array of pointer, sedangkan chain 2 dan seterusnya berhubungan dengan chain 1 secara memanjang.
Kelemahan dari open hashing adalah bila data menumpuk pada satu/sedikit indeks sehingga terjadi linked list yang panjang.
Binary Tree
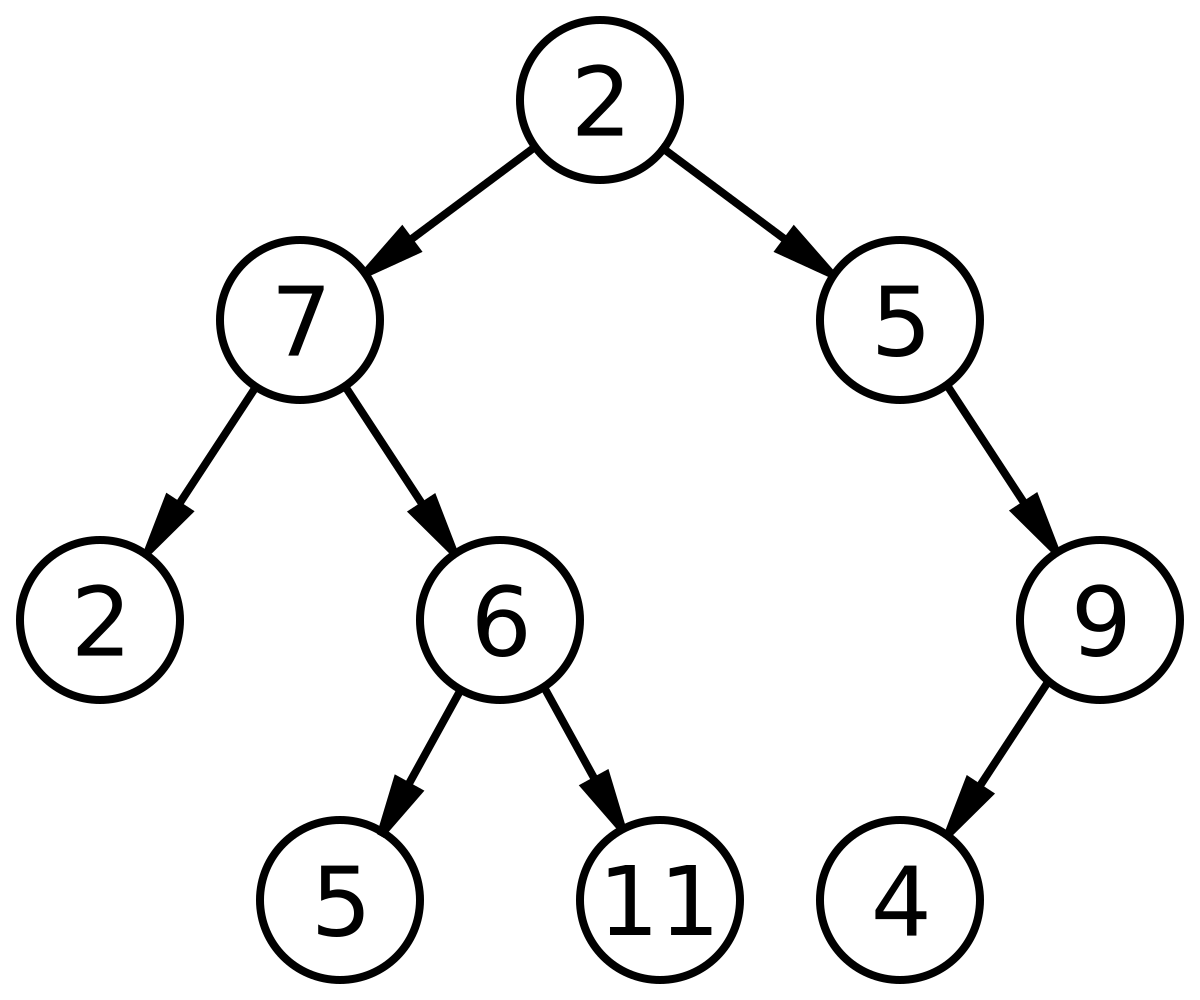
Binary Tree atau Pohon Biner adalah sebuah pohon dalam struktur data yang bersifat hirarkis (hubungan one to many). Tree bisa didefenisikan sebagai kumpulan simpul dengan setiap simpul mempunyai paling banyak dua anak. Secara khusus, anaknya dinamakan kiri dan kanan. Binary tree tidak memiliki lebih dari tiga level dari Root.
Binary tree adalah suatu tree dengan syarat bahawa tiap node (simpul) hanya boleh memiliki maksimal dua subtree dan kedua subtree tersebut harus terpisah. Tiap node dalam binary treee boleh memiliki paling banyak dua child (anak simpul), secara khusus anaknya dinamakan kiri dan kanan.
Pohon biner dapat juga disimpan sebagai struktur data implisit dalam array, dan jika pohon tersebut merupakan sebuah pohon biner lengkap, metode ini tidak boros tempat. Dalam penyusunan yang rapat ini, jika sebuah simpul memiliki indeks i, anaknya dapat ditemukan pada indeks ke-2i+1 dan 2i+2, meskipun ayahnya (jika ada) ditemukan pada indeks lantai ((i-1)/2) (asumsikan akarnya memiliki indeks kosong).
Binary tree adalah suatu tree dengan syarat bahawa tiap node (simpul) hanya boleh memiliki maksimal dua subtree dan kedua subtree tersebut harus terpisah. Tiap node dalam binary treee boleh memiliki paling banyak dua child (anak simpul), secara khusus anaknya dinamakan kiri dan kanan.
Pohon biner dapat juga disimpan sebagai struktur data implisit dalam array, dan jika pohon tersebut merupakan sebuah pohon biner lengkap, metode ini tidak boros tempat. Dalam penyusunan yang rapat ini, jika sebuah simpul memiliki indeks i, anaknya dapat ditemukan pada indeks ke-2i+1 dan 2i+2, meskipun ayahnya (jika ada) ditemukan pada indeks lantai ((i-1)/2) (asumsikan akarnya memiliki indeks kosong).
Binary Search Tree

Binary search tree memungkinkan pencarian dengan cepat, penambahan, juga menghapus data yang ada di dalamnya, bisa juga digunakan sebagai implementasi sejumlah data dinamis, atau pencarian table data dengan menggunakan informasi kunci atau key.
Aturan main Binary Search Tree :
- Setiap child node sebelah kiri harus lebih kecil nilainya daripada root nodenya.
- Setiap child node sebelah kanan harus lebih besar nilainya daripada root nodenya.
Lalu, ada 3 jenis cara untuk melakukan penelusuran data (traversal) pada BST :
- PreOrder : Print data, telusur ke kiri, telusur ke kanan
- InOrder : Telusur ke kiri, print data, telusur ke kanan
- Post Order : Telusur ke kiri, telusur ke kanan, print data
Berikut adalah contoh implementasi Binary Search Tree pada C beserta searching datanya :
#include <stdio.h>
#include <stdlib.h>
//inisialisasi struct
struct data{
int number;
//pointer untuk menampung percabangan kiri dan kanan
data *left, *right;
}*root;
//fungsi push untuk menambah data
void push(data **current, int number){
//jika pointer current kosong maka akan membuat blok data baru
if((*current)==NULL){
(*current) = (struct data *)malloc(sizeof data);
//mengisi data
(*current)->number=number;
(*current)->left = (*current)->right = NULL;
//jika tidak kosong, maka akan dibandingkan apakah angka yang
//ingin dimasukkan lebih kecil dari pada root
//kalau iya, maka belok ke kiri dan lakukan rekursif
//terus menerus hingga kosong
}else if(number < (*current)->number){
push(&(*current)->left, number);
//jika lebih besar, belok ke kanan
}else if(number >= (*current)->number){
push(&(*current)->right, number);
}
}
//preOrder : cetak, kiri, kanan
void preOrder(data **current){
if((*current)!=NULL){
printf("%d -> ", (*current)->number);
preOrder(&(*current)->left);
preOrder(&(*current)->right);
}
}
//inOrder : kiri, cetak, kanan
void inOrder(data **current){
if((*current)!=NULL){
inOrder(&(*current)->left);
printf("%d -> ", (*current)->number);
inOrder(&(*current)->right);
}
}
//postOrder : kiri, kanan, cetak
void postOrder(data **current){
if((*current)!=NULL){
postOrder(&(*current)->left);
postOrder(&(*current)->right);
printf("%d -> ", (*current)->number);
}
}
//searching data
void search(data **current, int number){
//jika pointer current memiliki data
if((*current)!=NULL){
//cek, apakah datanya lebih kecil. Jika iya, belok ke kiri
if(number<(*current)->number){
search(&(*current)->left,number);
//jika lebih besar, maka belok ke kanan
}else if(number>(*current)->number){
search(&(*current)->right,number);
//jika sama dengan, maka angka ketemu
}else{
printf("Found : %d", (*current)->number);
}
//jika tidak ada data lagi (not found)
}else{
printf("Not Found.");
}
}
void main(){
push(&root, 11);
push(&root, 22);
push(&root, 13);
push(&root, 15);
push(&root, 9);
inOrder(&root);
printf("\n");
preOrder(&root);
printf("\n");
postOrder(&root);
printf("\n");
search(&root,91);
getchar();
}
sumber :



Komentar
Posting Komentar